AI芯片新贵,各出奇招
热搜大全 2024-03-11

光芯片,速度惊人
最近两年的人工智能繁荣,让英伟达凭借 GPU 登上了芯片之巅。于是包括 AMD、Intel、Graphcore、Cerebras 和 Tenstorrent 等在内的传统和新贵芯片企业试图在这个领域将英伟达拉下马。
不过,虽然他们都非常努力,但似乎依然难动英伟达分毫。于是,市场上又冒出来了一群 AI 芯片新公司,他们希望用不同的架构和思路,以期将英伟达赶下神坛。
下面我们来盘点一下最近比较热门的挑战者。
每个模型都要有相应的 AI 芯片
这是来自 Taalas 公司创始人 Ljubisa Bajic 的观点。提示一下,Ljubisa Bajic 还有一个身份,那就是他也是 Tenstorrent 的创始人,Jim keller 曾经亲密的合作伙伴。
在离开 Tenstorrent 一年之后,Ljubisa Bajic 终于在最近带来了他的新公司。
Ljubisa Bajic 表示,即使是当今的专用人工智能芯片也过于通用化,无法满足其需要。他的新初创公司 Taalas(印地语是锁匠的意思)承诺通过开发最终针对特定型号的架构和芯片,将效率障碍再次突破几个数量级。
据介绍,新公司已从 Quiet Capital 和 Pierre Lamond 处通过两轮迷你融资(1200 万美元和 3800 万美元)筹集了 5000 万美元,根据他们的设想,硅可以在制造时进一步优化以适应特定型号。虽然人工智能和机器学习在软件和硬件方面都在快速发展,但我们开始看到 " 足够好 " 模型的趋势,专用计算路径确实预示着更专用、更高效的芯片方法。
我们认为 Taalas 最终将使用一种强化的可配置硬件——存在于真正固定功能 ASIC/DSP 或完全可重新配置的硬件解决方案(如 FPGA 或 CGRA)(两者都具有在人工智能领域也找到了利基)。该领域的许多芯片设计公司都运行 eASIC(即结构化 ASIC)业务,其中底层硬件是可配置的,但在最终制造时可以锁定为给定的配置。这使得制造过程仍然可以创建通用可编程芯片,但可以减少部署到客户市场的可重新配置开销。

据 Taalas 称,这解决了当今人工智能硬件的两个主要问题——功效和成本。机器学习在消费者日常生活中的预期普及程度将像电力一样无处不在,因此它将存在于从汽车到白色家电到智能电表以及所有可以电气化的堆栈中的一切事物中。为了满足成本、计算能力 / 效率的需求,以及这些设备中的一些 / 大多数设备永远不会连接到互联网的事实,该硬件需要在部署时专用并固定。只有当计算工作负载固定(或简单)时才会发生这种情况,Taalas 和 Ljubisa 认为这是一个即将到来的前沿领域(如果今天还没有出现的话)。
在新闻稿中他们 Ljubisa Bajic 表示:" 人工智能就像电力——一种需要向所有人提供的基本商品。人工智能的商品化需要计算能力和效率提高 1000 倍,这是通过当前渐进方法无法实现的目标。前进的道路是实现 " 我们不应该在通用计算机上模拟智能,而应该将智能直接注入硅中。在硅中实施深度学习模型是实现可持续人工智能的最直接途径。"
Taalas 正在开发一种自动化流程,用于在硅中快速实施所有类型的深度学习模型(Transformers、SSM、Diffusers、MoE 等)。专有的创新使其一款芯片能够容纳整个大型人工智能模型,而无需外部存储器。硬连线计算的效率使单个芯片的性能优于小型 GPU 数据中心,从而为 AI 成本降低 1000 倍开辟了道路。
" 我们相信 Taalas 的‘ direct to silicon ’代工厂实现了三项根本性突破:大幅重置当今人工智能的成本结构,切实可行地实现模型尺寸接下来 10-100 倍的增长,以及在任何消费设备上本地高效运行强大的模型。Quiet Capital 合伙人 Matt Humphrey 表示:" 对于人工智能未来的可扩展性而言,这可能是当今计算领域最重要的使命。我们很自豪能够支持这个出色的 n-of-1 团队来完成这件事。"
简而言之,如果您需要在产品中使用具有 7B 参数的 Llama2 型号,并且该公司确定这就是它在整个生命周期中所需要的全部,那么可以为该手持设备提供最低功耗和最低成本的专用硬核 Llama2-7B 芯片和型号设备就是您可能需要的一切。
据了解,Taalas 团队位于加拿大多伦多,拥有来自 AMD、NVIDIA 和 Tenstorrent 的专业知识。该公司将于 2024 年第三季度推出首款大型语言模型芯片,并计划于 2025 年第一季度向早期客户提供。
韩国 AI 芯片:功耗和尺寸大幅下降
来自韩国科学技术院 ( KAIST ) 的科学家团队在最近的 2024 年国际固态电路会议 ( ISSCC ) 上详细介绍了他们的 "Complementary-Transformer" 人工智能芯片。新型 C-Transformer 芯片据称是全球首款能够进行大语言模型(LLM)处理的超低功耗 AI 加速器芯片。
在一份新闻稿中,研究人员对疯狂叫板 Nvidia ,声称 C-Transformer 的功耗比绿色团队的 A100 Tensor Core GPU 低 625 倍,尺寸小 41 倍。它还表明,三星晶圆代工芯片的成就很大程度上源于精细的神经拟态计算技术。
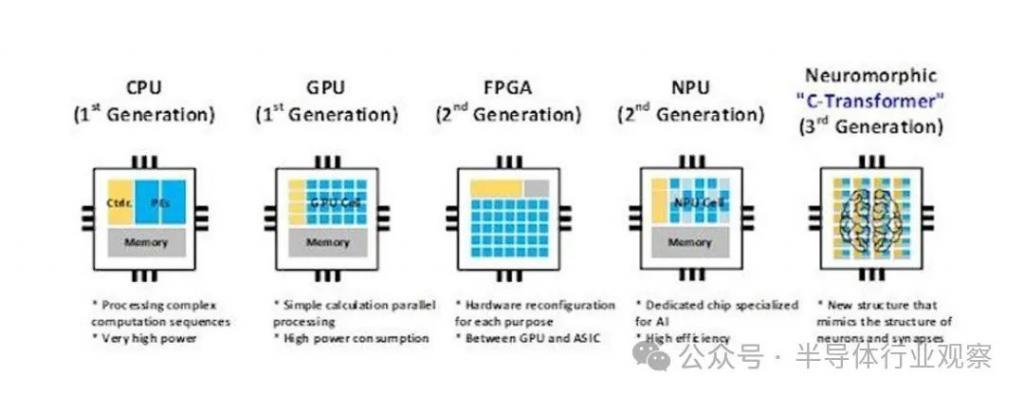
尽管我们被告知 KAIST C-Transformer 芯片可以完成与 Nvidia 强大的 A100 GPU 之一相同的 LLM 处理任务,但我们在新闻或会议材料中都没有提供任何直接的性能比较指标。这是一个重要的统计数据,由于它的缺失而引人注目,愤世嫉俗的人可能会猜测性能比较不会给 C-Transformer 带来任何好处。

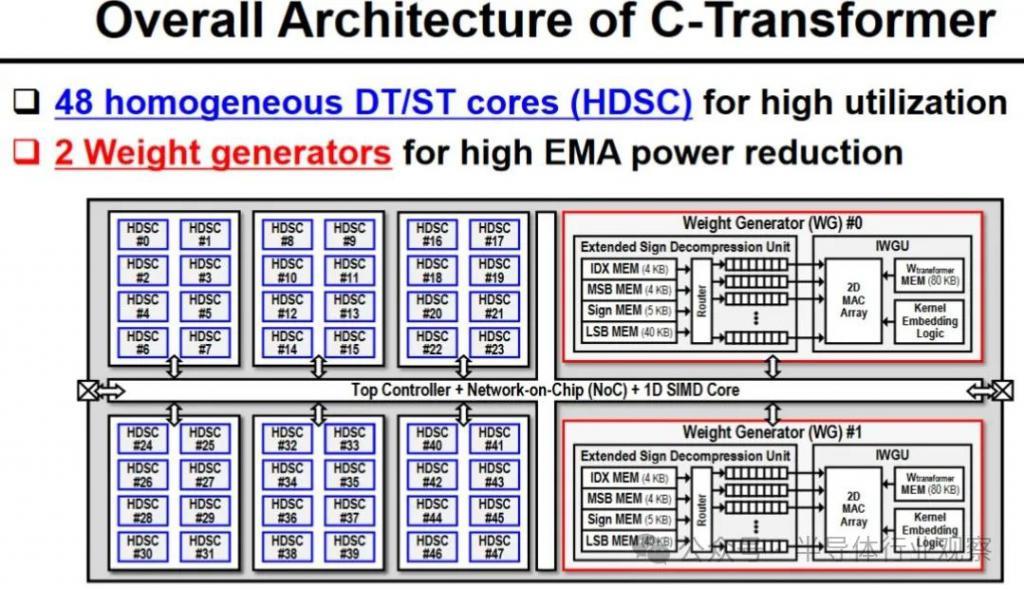

上面的图片有一张 " 芯片照片 " 和处理器规格的摘要。您可以看到,C-Transformer 目前采用三星 28nm 工艺制造,芯片面积为 20.25mm2。它的最高运行频率为 200 MHz,功耗低于 500mW。最好的情况下,它可以达到 3.41 TOPS。从表面上看,这比 Nvidia A100 PCIe 卡声称的 624 TOPS 慢 183 倍(但 KAIST 芯片据称使用的功率低 625 倍)。然而,我们更喜欢某种基准性能比较,而不是查看每个平台声称的 TOPS。
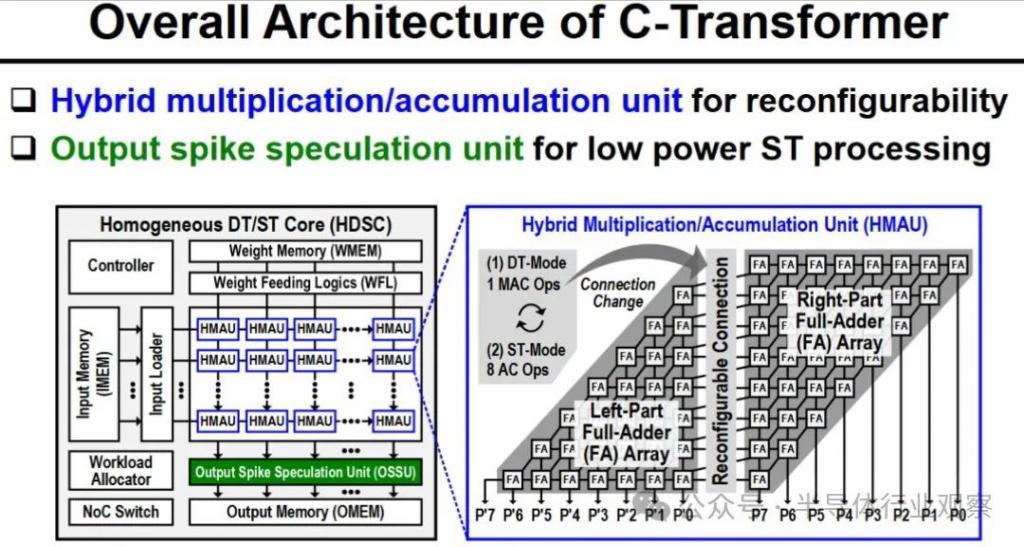
C-Transformer 芯片的架构看起来很有趣,其特点是三个主要功能块:首先,Homogeneous DNN-Transformer / Spiking-transformer Core ( HDSC ) 和混合乘法累加单元 ( HMAU:Hybrid Multiplication-Accumulation Unit ) 可以有效处理动态变化的分布能量。其次,我们有一个输出尖峰推测单元(OSSU:Output Spike Speculation Unit)来减少尖峰域处理的延迟和计算量。第三,研究人员实施了带有扩展符号压缩(ESC:Extended Sign Compression)的隐式权重生成单元(IWGU:Implicit Weight Generation Unit),以减少外部存储器访问(EMA)能耗。
据解释,C-Transformer 芯片不仅仅添加了一些现成的神经拟态处理作为其压缩 LLM 大参数的 "special sauce"。韩国科学技术院的新闻稿称,此前,神经拟态计算技术对于法学硕士的使用不够准确。然而,研究团队表示,它 " 成功提高了该技术的准确性,以匹配 [ 深度神经网络 ] DNN"。
尽管由于没有与行业标准人工智能加速器进行直接比较,第一款 C-Transformer 芯片的性能存在不确定性,但毫无疑问,它将成为移动计算的一个有吸引力的选择。同样令人鼓舞的是,研究人员利用三星测试芯片和广泛的 GPT-2 测试取得了如此大的进展。
彻底改变人工智能的芯片
最近,普林斯顿大学的先进人工智能芯片项目由 DARPA 和 EnCharge AI 支持,有望显着提高能源效率和计算能力,旨在彻底改变人工智能的可及性和应用。
普林斯顿大学电气和计算机工程教授纳文 · 维尔马 ( Naveen Verma ) 表示,新硬件针对现代工作负载重新设计了人工智能芯片,并且可以使用比当今最先进的半导体少得多的能源运行强大的人工智能系统。领导该项目的维尔马表示,这些进步突破了阻碍人工智能芯片发展的关键障碍,包括尺寸、效率和可扩展性。
" 最好的人工智能仅存在于数据中心,有一个非常重要的限制," 维尔马说。" 我认为,你从中解锁了它,我们从人工智能中获取价值的方式将会爆炸。"
在普林斯顿大学领导的项目中,研究人员将与 Verma 的初创公司 EnCharge AI 合作。EnCharge AI 总部位于加利福尼亚州圣克拉拉,正在将基于 Verma 实验室发现的技术商业化,其中包括他早在 2016 年与电气工程研究生共同撰写的几篇重要论文。
根据项目提案,Encharge AI" 在强大且可扩展的混合信号计算架构的开发和执行方面处于领先地位 "。Verma 于 2022 年与前 IBM 院士 Kailash Gopalakrishnan 和半导体系统设计领域的领导者 Echere Iroaga 共同创立了该公司。
Gopalakrishnan 表示,当人工智能开始对计算能力和效率产生大量新需求时,现有计算架构的创新以及硅技术的改进开始放缓。即使是用于运行当今人工智能系统的最好的图形处理单元 ( GPU ) ,也无法缓解行业面临的内存和计算能源瓶颈。
" 虽然 GPU 是当今最好的可用工具," 他说," 但我们得出的结论是,需要一种新型芯片来释放人工智能的潜力。"
普林斯顿大学 凯勒工程教育创新中心主任 Verma 表示,从 2012 年到 2022 年,人工智能模型所需的计算能力实现了指数级增长。为了满足需求,最新的芯片封装了数百亿个晶体管,每个晶体管之间的宽度只有一个小病毒的宽度。然而,这些芯片的计算能力仍然不足以满足现代需求。
当今的领先模型将大型语言模型与计算机视觉和其他机器学习方法相结合,每个模型都使用超过一万亿个变量来开发。推动人工智能热潮的英伟达设计的 GPU 变得非常有价值,据报道,各大公司都通过装甲车运输它们。购买或租赁这些芯片的积压已经达到了消失的程度。
为了创建能够在紧凑或能源受限的环境中处理现代人工智能工作负载的芯片,研究人员必须完全重新构想计算的物理原理,同时设计和封装可以使用现有制造技术制造并且可以与现有计算技术良好配合的硬件,例如中央处理单元。
" 人工智能模型的规模呈爆炸式增长," 维尔马说," 这意味着两件事。" 人工智能芯片需要在数学计算方面变得更加高效,在管理和移动数据方面也需要更加高效。
他们的方法分为三个关键部分。
几乎每台数字计算机的核心架构都遵循 20 世纪 40 年代首次开发的看似简单的模式:在一个地方存储数据,在另一个地方进行计算。这意味着在存储单元和处理器之间传输信息。在过去的十年中,Verma 率先研究了一种更新方法,其中计算直接在内存单元中完成,称为内存计算。这是第一部分。内存计算有望减少移动和处理大量数据所需的时间和能源成本。
但到目前为止,内存计算的数字方法还非常有限。维尔马和他的团队转向了另一种方法:模拟计算。那是第二部分。
" 在内存计算的特殊情况下,你不仅需要高效地进行计算,"Verma 说," 你还需要以非常高的密度进行计算,因为现在它需要适合这些非常小的内存单元。" 模拟计算机不是将信息编码为一系列 0 和 1,然后使用传统逻辑电路处理该信息,而是利用设备更丰富的物理特性。
数字信号在 20 世纪 40 年代开始取代模拟信号,主要是因为随着计算的指数级增长,二进制代码可以更好地扩展。但数字信号并没有深入了解设备的物理原理,因此,它们可能需要更多的数据存储和管理。这样他们的效率就较低。模拟通过利用设备的固有物理特性处理更精细的信号来提高效率。但这可能会牺牲精度。
维尔马说:" 关键在于找到适合该工作的物理原理,使设备能够被很好地控制并大规模制造。"
他的团队找到了一种方法,使用专门设计用于精确开关的电容器生成的模拟信号来进行高精度计算。这是第三部分。与晶体管等半导体器件不同,通过电容器传输的电能不依赖于材料中的温度和电子迁移率等可变条件。
" 它们只依赖于几何形状," 维尔马说。" 它们取决于一根金属线和另一根金属线之间的空间。" 几何形状是当今最先进的半导体制造技术可以控制得非常好的一件事。
光芯片,速度惊人
宾夕法尼亚大学的工程师开发了一种新芯片,它使用光波而不是电力来执行训练人工智能所必需的复杂数学。该芯片有可能从根本上加快计算机的处理速度,同时降低能耗。
该硅光子 ( SiPh ) 芯片的设计首次将本杰明 · 富兰克林奖章获得者和 H. Nedwill Ramsey 教授 Nader Engheta 在纳米级操纵材料方面的开创性研究结合在一起,利用光(可能是最快的通信方式)进行数学计算 SiPh 平台使用硅,硅是一种廉价且丰富的元素,用于大规模生产计算机芯片。
光波与物质的相互作用代表了开发计算机的一种可能途径,这种计算机可以取代当今芯片的局限性,这些芯片本质上与 20 世纪 60 年代计算革命初期的芯片相同的原理。
在《自然光子学》杂志上发表的一篇论文中,Engheta 的团队与电气和系统工程副教授 Firooz Aflatouni 的团队一起描述了新芯片的开发过程。
" 我们决定联手,"Engheta 说道,他利用了 Aflatouni 的研究小组率先开发纳米级硅器件的事实。
他们的目标是开发一个平台来执行所谓的向量矩阵乘法,这是神经网络开发和功能中的核心数学运算,神经网络是当今人工智能工具的计算机架构。
Engheta 解释说," 你可以将硅做得更薄,比如 150 纳米 ",而不是使用高度均匀的硅晶片,但仅限于特定区域。这些高度的变化(无需添加任何其他材料)提供了一种控制光在芯片中传播的方法,因为高度的变化可以分布以使光以特定的图案散射,从而使芯片能够执行数学计算以光速。
Aflatouni 表示,由于生产芯片的商业代工厂施加的限制,该设计已经为商业应用做好了准备,并且有可能适用于图形处理单元 ( GPU ) ,随着广泛应用,图形处理单元 ( GPU ) 的需求猛增。对开发新的人工智能系统的兴趣。
" 他们可以采用硅光子平台作为附加组件,"Aflatouni 说," 然后就可以加快训练和分类速度。"
除了更快的速度和更少的能耗之外,Engheta 和 Aflatouni 的芯片还具有隐私优势:由于许多计算可以同时进行,因此无需在计算机的工作内存中存储敏感信息,使得采用此类技术的未来计算机几乎无法被黑客攻击。
" 没有人可以侵入不存在的内存来访问你的信息," 阿弗拉图尼说。
其他合著者包括宾夕法尼亚大学工程学院的 Vahid Nikkhah、Ali Pirmoradi、Farshid Ashtiani 和 Brian Edwards。