李开复再度回应争议:行业逐渐形成通用标准,我们取之开源也贡献开源
热搜大全 2023-11-16
腾讯科技讯 (陈书)11 月 15 日,李开复针对零一万物近日陷入的争议风波在朋友圈再度发文回应:" 就像做一个手机 App 开发者,不会去自创 iOS、Android 以外的全新基础架构。01.AI 起步受益于开源,也贡献开源,从社区中虚心学习,我们会持续进步。"
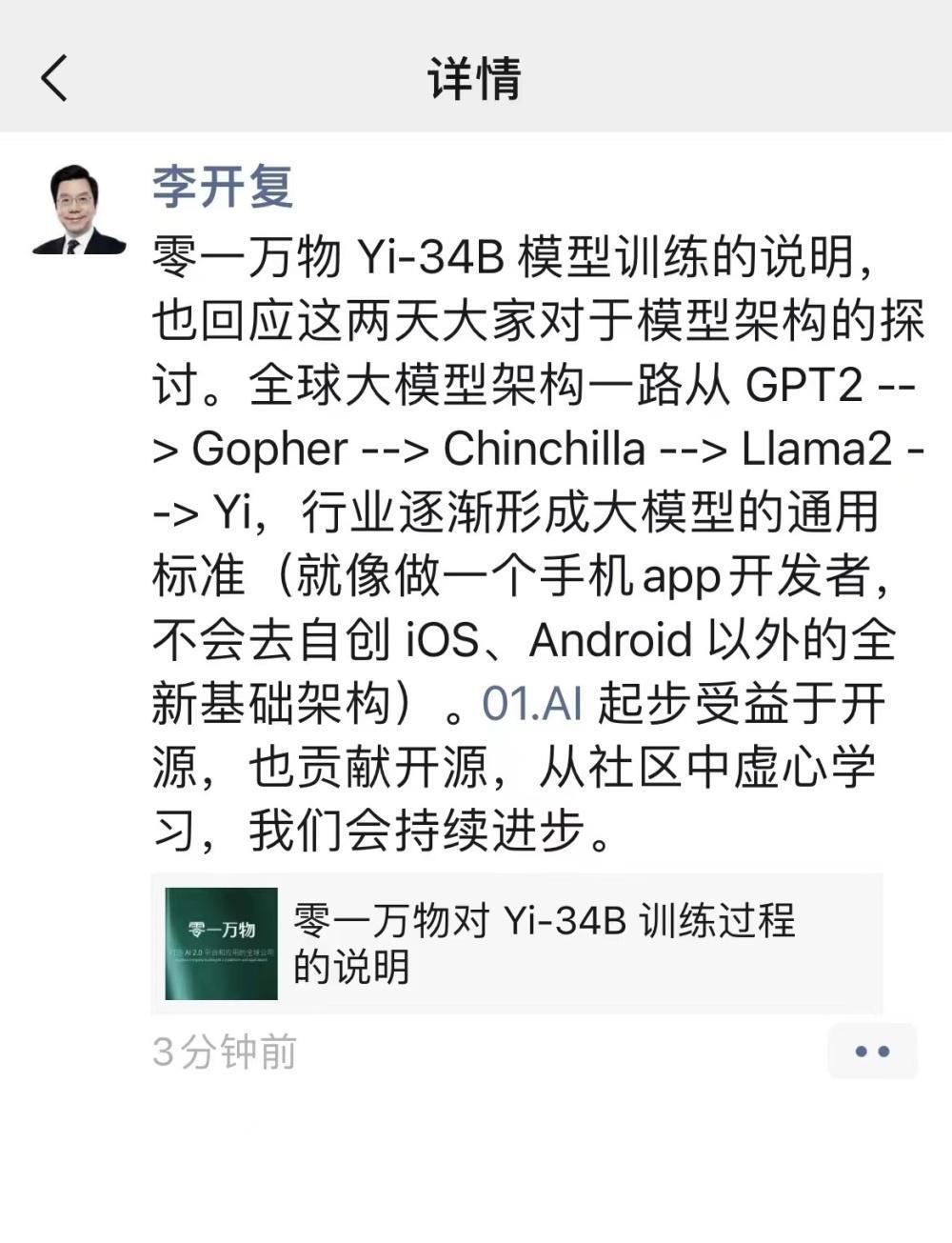
李开复朋友圈回应
零一万物的 " 争议风波 ",发酵于今年 3 月份从阿里离职投身 AI 大模型创业的贾扬清,他在朋友圈爆料称:" 在帮助海外客户适配国内某一新模型中,被朋友告知该模型用的其实是 LLaMA 架构,仅在代码中更改了几个变量名。"
尽管他并未点出开发上述涉及的 " 大厂 " 是指哪家,李开复博士带队创办的创业公司零一万物却因为近期的发布被带风口浪尖。11 月 6 日,零一万物刚刚发布了 "Yi" 系列开源大模型—— Yi-34B 和 Yi-6B。
针对外界质疑,11 月 14 日零一万物曾进行回应,承认 " 在训练模型过程中,沿用了 GPT/LLaMA 的基本架构 "。
"GPT 是一个业内公认的成熟架构,LLaMA 在 GPT 上做了总结。零一万物研发大模型的结构设计基于 GPT 成熟结构,借鉴了行业顶尖水平的公开成果,同时基于零一万物团队对模型和训练的理解做了大量工作,这是我们首次发布获得优秀结果的地基之一。与此同时,零一万物也在持续探索模型结构层面本质上的突破。模型结构仅是模型训练其中一部分。Yi 开源模型在其他方面的精力,比如数据工程、训练方法、baby sitting(训练过程监测)的技巧、hyperparameter 设置、评估方法以及对评估指标的本质理解深度、对模型泛化能力的原理的研究深度、行业顶尖的 AI Infra 能力等,投入了大量研发和打底工作,这些工作往往比起基本结构能起到更大的作用跟价值,这些也是零一万物在大模型预训练阶段的核心技术护城河。在大量训练实验过程中,由于实验执行需求对代码做了更名,我们尊重开源社区的反馈,将代码进行更新,也更好的融入 Transformer 生态。我们非常感谢社区的反馈,我们在开源社区刚刚起步,希望和大家携手共创社区繁荣,Yi Open-source 会尽最大努力持续进步。"
但是这个解释,并未平息外界争议,因此,李开复博士及零一万物 CMO 继续发声,回应 " 争议风波 "。同时,11 月 15 日零一万物也在官方公众号公布了 Yi-34B 的训练过程:

零一万物公布训练过程
一、是否是 " 抄袭 ",AI 业内人士这样说
关于如何定义 " 抄袭 ",腾讯科技也咨询了几位大模型领域的开发人员,反馈的意见如下:
基于开源架构的 " 修改 ",很难定义是否为抄袭,但凡做出一些优化,其实都不能算抄袭。开源社区的很多优秀项目都是基于一点点的 " 优化 " 而来。
猴子无限的创始人尹伯昊(猴子无限是一家去年 8 月成立的 AI 公司,专注于模型调优)在朋友圈表示:" 同样的框架能够做出完全不同的模型,大模型训练是一个充分的系统工程,不是使用了一个现有框架就是抄袭,因此否定团队价值是不负责任的。"

二、争议源起于开源社区,开源社区如何看?
其实在贾扬清发布朋友圈之前,关于零一万物的争议首先在开源社区内发酵:
9 天前,convai 高级人工智能应用专家埃里克 · 哈特福德在 Huggingface 上发帖称,"Yi-34B 模型基本采用了 LLaMA 的架构,只是重命名了两个张量。"
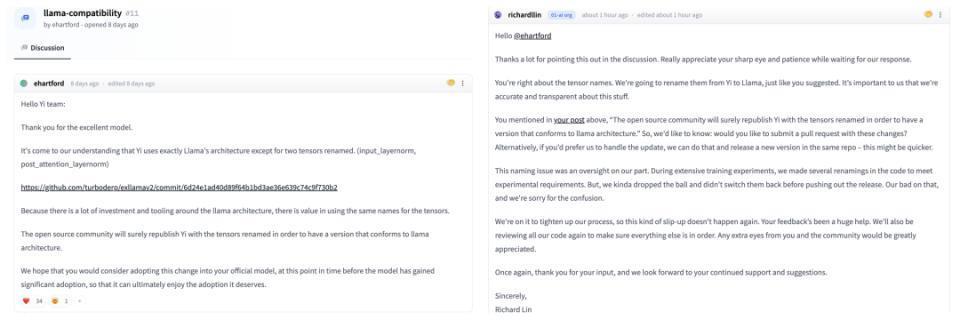
11 月 14 日,Yi 团队开源总监 Richard Lin 在该帖下回复称,哈特福德对张量名称的看法是正确的,零一万物将把它们从 Yi 重命名为 Llama。
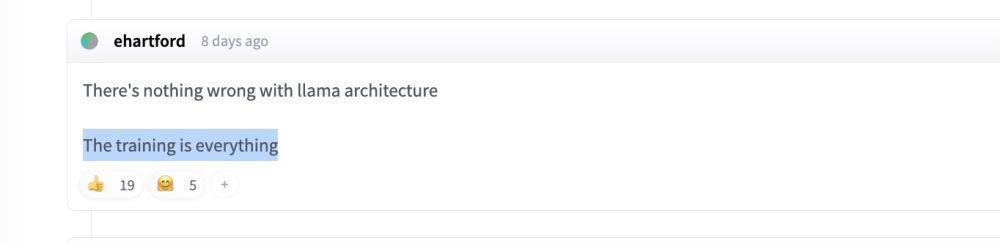
在 HuggingFace 上,有开发者发帖称 "Training is everything"(模型架构没问题,训练方法更重要)。
在国内的某社区平台,也看到相关开发者反馈意见," 模型架构的设计根本不是痛点,优质的训练数据才是。"