只看了你一“眼”,AI 就能预测帕金森?
热搜大全 2023-10-20
文 | 追问 NextQuestion,作者 | 铸雪,编辑 | lixia
近年来,随着深度学习技术的发展,医疗人工智能(医疗 AI)在基于视网膜图像判定人体健康状况、诊断潜在眼部和全身性疾病等领域,具有巨大潜力。然而,AI 模型的开发往往需要大量的标记,这些标记通常只针对特定任务,因而对不同临床应用的泛化能力十分有限。
近日,在 nature 杂志上发表的一篇研究介绍了基础模型 RETFound ——一个针对视网膜图像的大模型。RETFound 能从未标记的视网膜图像中学习可泛化的表征,具体而言,RETFound 通过自监督学习的方法在 160 万张未标记的视网膜图像上进行训练,然后通过微调来适应具有明确标记的疾病检测任务。
科学家们展示了微调后的 RETFound 在诊断和预测眼部疾病方面的能力,以及在较少标记数据的情况下,对于复杂的全身性疾病(如心力衰竭和心肌梗死)的预测能力,发现它的表现始终优于其他模型。
总之,RETFound 提供了一个可泛化的解决方案,能提高模型性能并减轻专家标记工作的负担,从而实现了基于视网膜图像的 AI 更广泛的临床应用。

▷图 1:论文封面。图源:nature 官网
从心灵的窗户窥见疾病的端倪
毋庸置疑,医疗 AI 的发展之迅速,在不少医疗领域已达到,甚至超越了临床专家的准确度,比如在进行对威胁视力的视网膜疾病的转诊建议、胸部 X 射线图像的病理学检测等。
但上述模型是基于大量高质量的标记开发完成的,这样的标记需要大量的专家评估,对医生而言是一项繁重的工作负担。更为重要的是,由于具有相关领域知识的专家十分稀缺,无法满足 AI 对于标记的要求,这也导致大量医疗数据未被标记,无法被有效利用。
对此,深度学习中的自监督学习(self-supervised learning,SSL),或可提供解决思路。
SSL 通过直接从数据中获取监督信号来缓解数据效率低下的问题,而不是依靠专家标记。SSL 训练模型执行不需要标签或可以自动生成标签的 " 前置任务 ",该过程中模型利用大量未标记数据来学习通用特征的表征,从而轻松适应更具体的任务。
在预训练阶段之后,模型将针对特定的下游任务进行微调,例如分类或细分。在各种计算机视觉任务中,SSL 模型的性能优于基于监督学习的迁移学习(例如,使用 ImageNet 和分类标签来预训练模型)。除了提高标记的效率之外,在对来自不同领域的新数据进行测试时,基于 SSL 的模型比监督模型的表现更好。
强大的泛化表征能力,加之其在许多下游任务中通过微调模型实现的高性能,种种证据皆表明 SSL 在数据丰富、任务多样化但标记稀缺的医疗 AI 领域中具有巨大潜力。
彩色眼底摄影(colour fundus photography,CFP)和光学相干断层扫描(optical coherence tomography,OCT)是眼科最常见的成像方式,此类视网膜图像在常规临床实践中得以迅速积累。
除了能显示与眼部疾病相关的临床特征外,这些图像对于全身性疾病的诊断也很有价值。例如,视神经和视网膜内层摄影提供了中枢神经系统组织的非侵入性影像,从而为医生提供了了解病人神经病变的窗口。同样地,视网膜血管的几何形状也有利于医生深入了解其他器官(如心脏和肾脏)。
视网膜图像 SSL 模型,一个基于自监督学习的视网膜图像基础模型由此诞生了。
RETFound:视网膜图像基础模型
在这项研究中,科学家通过 SSL 利用大量未标记的视网膜图像构建了 RETFound,并用其促进多种疾病的检测。
具体而言,科研团队开发了两个独立的 RETFound 模型,一个基于 CFP,另一个基于 OCT,通过掩码自编码器(一种 SSL 技术),依次对自然图像(ImageNet-1k)、Moorfields 糖尿病图像数据集(MEH-MIDAS)的视网膜图像和公共数据(共计 904170 个 CFP 数据和 736442 个 OCT 数据)进行分析。
然后,科学家通过使用特定任务标签微调 RETFound,使 RETFound 可以适应一系列具有挑战性的诊断和预测任务,并验证其性能。
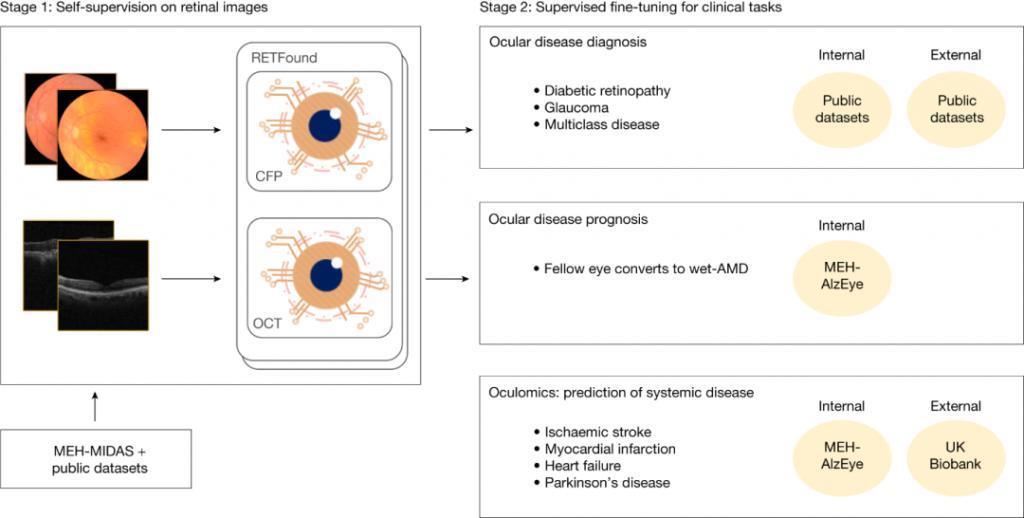
▷图 2.RETFound 基础模型的开发和评估示意图。阶段 1:使用来自 MEH-MIDAS 的 CFP 和 OCT 图像以及公共数据集,通过 SSL 构建 RETFound。阶段 2:通过内部和外部评估的监督学习使 RETFound 适应下游任务。图源:论文
图 2 概述了 RETFound 的构建和应用。为了构建 RETFound,科学家使用了 904170 幅 CFP 图像,其中 90.2% 的图像来自 MEH-MIDAS,9.8% 来自 Kaggle EyePACS;科学家同时采用了 736442 个 OCT 图像,其中 85.2% 来自 MEH-MIDAS,14.8% 来自其他参考文献。
MEH-MIDAS 是一个回溯数据集,包括 2000 年 1 月至 2022 年 3 月期间在 Moorfields 眼科医院就诊的 37401 名糖尿病患者的完整眼部成像记录。
在对这些视网膜图像进行自监督预训练后,科学家评估了模型在适应不同眼部和眼科任务方面的性能和通用性。验证时,他们首先考虑对眼部疾病的诊断,包括糖尿病视网膜病变和青光眼;
其次是眼科疾病的预后,特别是一年之内对侧眼(contralateral eye)向湿性血管性年龄相关性黄斑病变(wet AMD)转变的概率;
最后是其他与眼科相关的挑战,特别是基于视网膜图像的心血管疾病(缺血性中风、心肌梗死和心力衰竭)的三年预测和神经退行性疾病(帕金森病)的预测。
他们选择了公开可用的数据集来完成眼部疾病诊断的任务。详情见表 1。
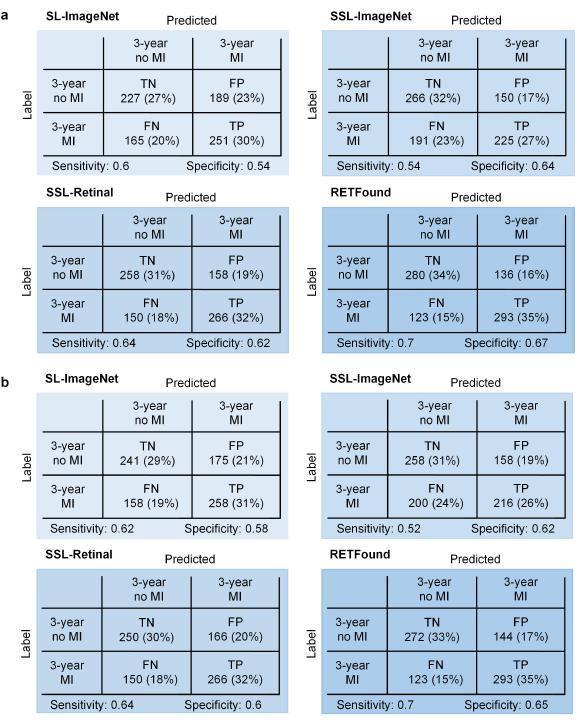
▷表 1. 心肌梗死 3 年预测的匹配矩阵。a,CFP 的混淆矩阵。b,OCT 的混淆矩阵。RETFound 较其他模型显示出最高的敏感性和特异性。表源:论文
对于眼部疾病预后和全身疾病预测的任务,研究团队使用了 Moorfields AlzEye 研究(MEH-AlzEye)的队列,该队列包含了 2008 年至 2018 年间在 Moorfields 眼科医院就诊的 353157 名患者的眼科数据,其中包含来自整个英格兰入院的系统性疾病数据。
RETFound vs. 传统模型
科研团队将 RETFound 的性能和标记效率与三个预训练的比较模型进行了比较:SL-ImageNet、SSL-ImageNet 和 SSL-Retinal。所有模型都使用不同的预训练策略,但具有相同的模型架构以及下游任务的微调过程,RETFound 的性能和标记效率始终占优。
SL-ImageNet 采用传统的迁移学习,即在 ImageNet-21k(约 1400 万张带有分类标签的自然图像)上通过监督学习的方式预训练模型;SSL-ImageNet 通过 SSL 在 ImageNet-1k(约 140 万张自然图像)上预训练模型,SSL-Retinal 通过 SSL 在视网膜图像上从头开始预训练模型。
RETFound 在扩展到视网膜图像之前使用 SSL-ImageNet 的权重作为基线(相当于在自然图像上使用 SSL 预训练模型,然后在视网膜图像上进行训练)。
在最新成果中,科学家们报告了这些模型的内部和外部评估结果。利用标记后的训练数据,这些模型可以适应每项任务,并在内部测试集以及与训练数据完全不同的外部数据集上进行评估。
此外,科学家使用接收者操作曲线下面积(area under the receiver operating curve,AUROC)和精确召回曲线下面积(area under the precision-recall curve,AUPR)来报告模型性能;同时使用 RETFound 和每个任务中最具竞争力的比较模型之间的双边 t 检验来计算 P 值,以检查模型的显著性。
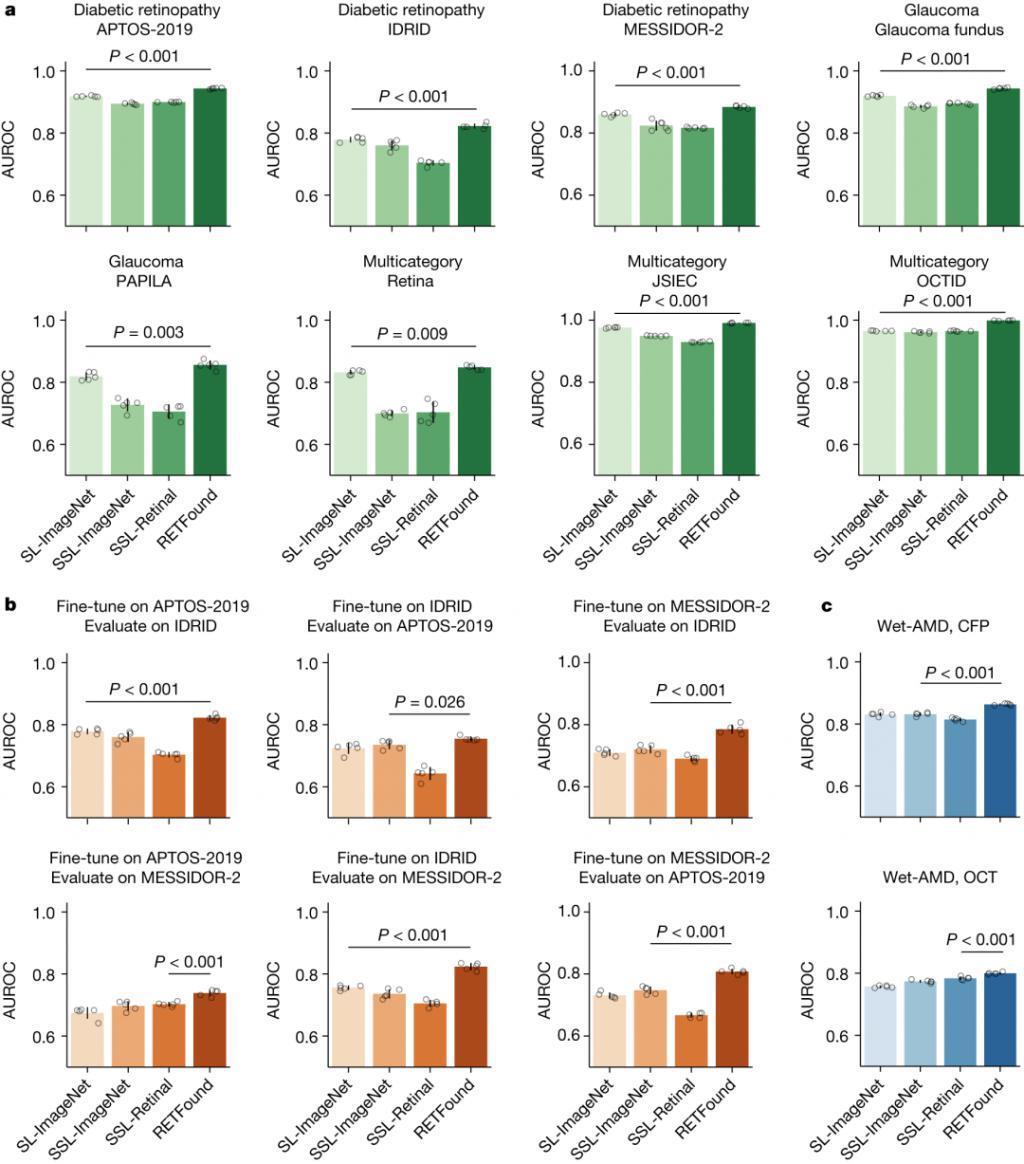
▷图 3. 不同模型对于眼部疾病诊断分类的表现。图源:论文
图 3 给出了不同模型对于眼部疾病诊断分类表现的内部评价、外部评价和预后表现。其中图 a 为内部评价。在诊断眼部疾病(如糖尿病视网膜病变和青光眼)的任务中,通过微调和内部评估来使模型适应每个数据集。图 b 为外部评估。
上述几个模型在一个糖尿病视网膜病变数据集上进行微调,并在其他数据集上进行外部评估。图 c 为预后表现。模型经过微调,可以预测 1 年内对侧眼向湿性 AMD 转变的概率,并进行内部评估。结果表明,RETFound 在所有任务中表现最佳。
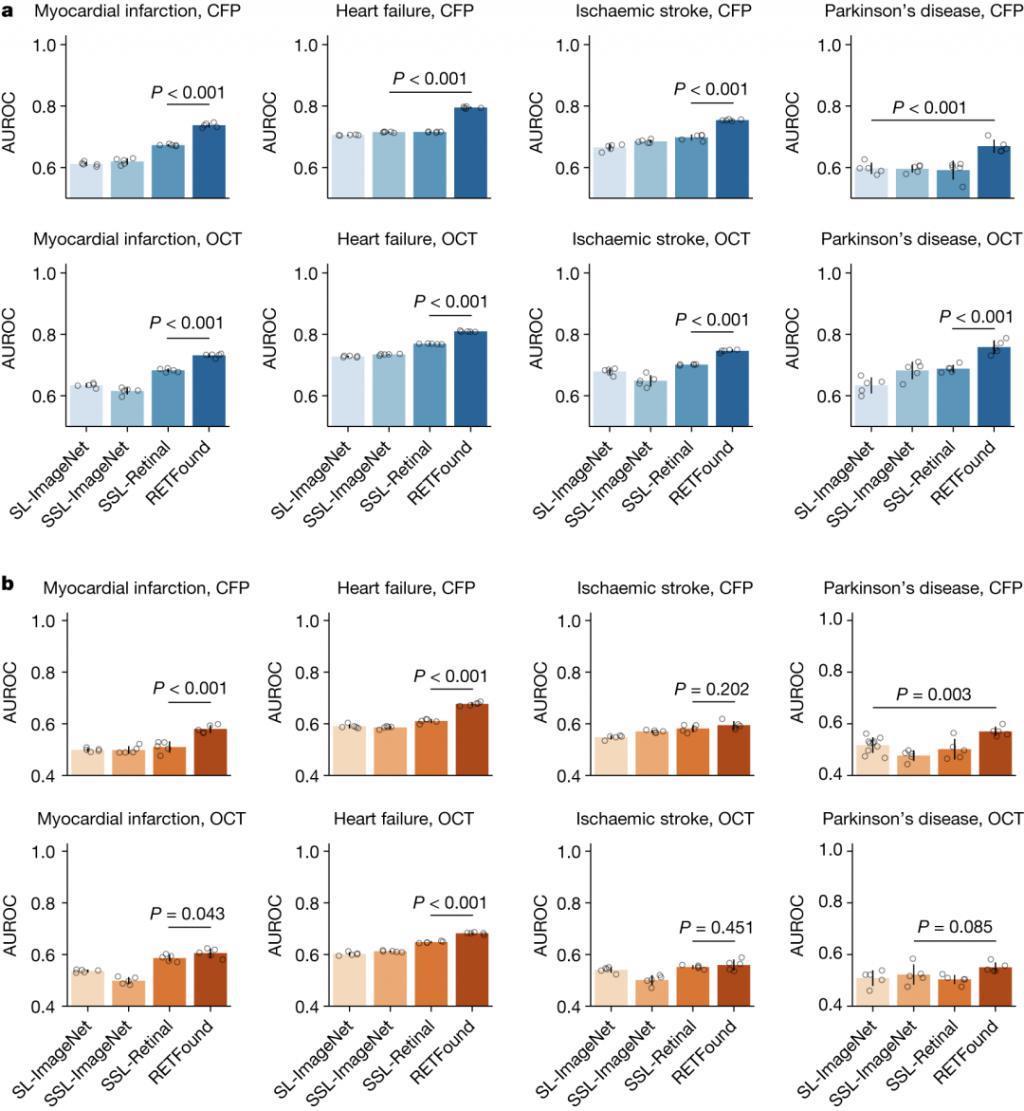
▷图 4. 不同模型利用视网膜图像预测全身性疾病 3 年发病率的表现。图源:论文
图 4 给出了不同模型利用视网膜图像预测全身性疾病 3 年发病率的表现。其中图 a 为内部评价。通过微调,模型可以适应 MEH-AlzEye 数据集。内部评估是基于测试集实现的。图 b 为外部评价。
模型在 MEH-AlzEye 上进行微调,并在 UK Biobank 上进行外部评估。尽管由于任务难度较高,几个模型整体表现不尽如人意,但 RETFound 在所有内部评估和大多数外部评估中 AUROC 都显著高于其他几个模型。
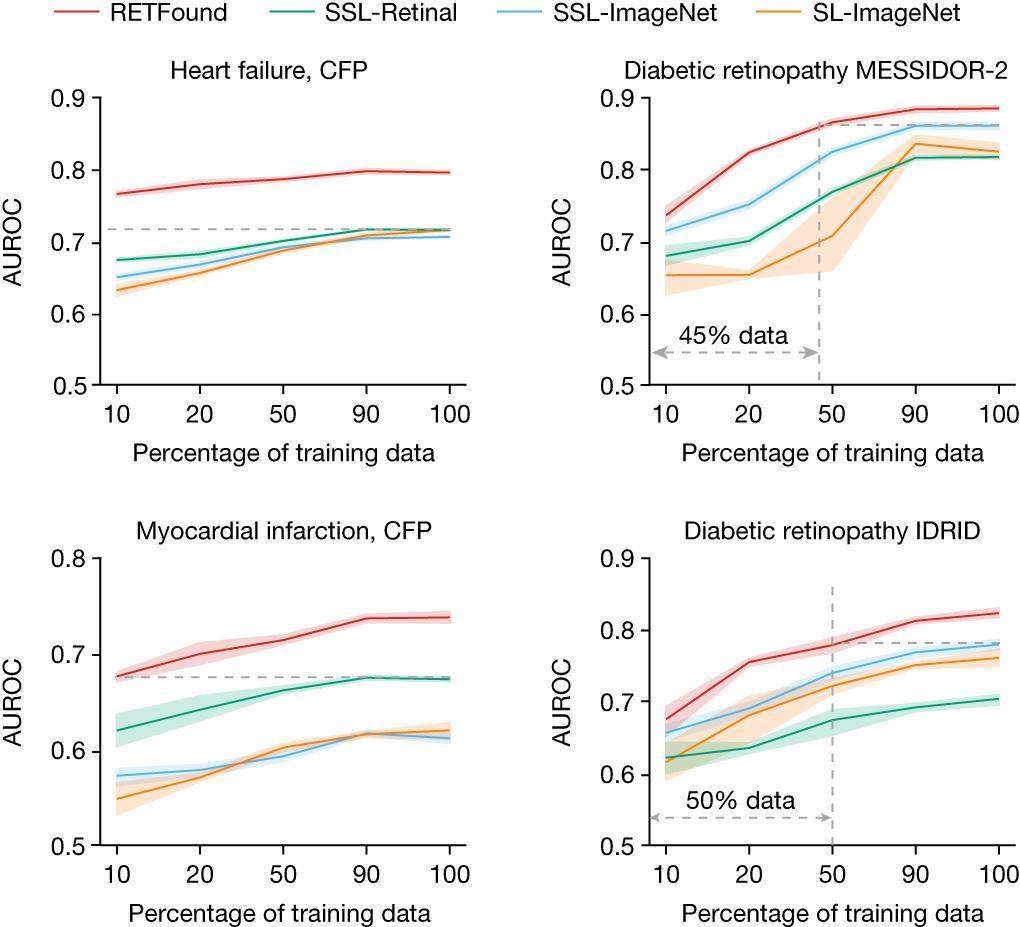
▷图 5. 几个典型应用场景中模型的标记效率。图源:论文
标记效率是衡量不同数量训练数据下模型的性能,以了解达到目标性能水平所需的数据量。图 5 中灰色虚线突出显示了 RETFound 和最具竞争力的模型之间所需训练数据的差异。
图像中不同颜色曲线代表不同模型的 AUROC,95% 置信区间,中心代表 AUROC 平均值。数据显示,在利用 CFP 图像预测心力衰竭和心肌梗死 3 年发病率两项任务中,RETFound 仅使用 10% 数据量,其表现就优于对照组模型。而在糖尿病视网膜病变相关的数据集 MESSIDOR-2 和 IDRID 上,RETFound 仅使用 45% 和 50% 的数据量,模型表现即可超越对照组模型。
尽管这项工作系统地评估了 RETFound 在诊断和预测多种疾病方面的作用,但仍存在一些限制和挑战,需要在未来的工作中进行探索。
首先,用于开发 RETFound 的大多数数据都来自英国,因此需要考虑未来引入全球视网膜图像后可能对模型效果带来的影响,模型有必要引入更加多样化和平衡的数据。
其次,虽然这项研究探索了 CFP 和 OCT 下模型的性能,但尚未研究 CFP 和 OCT 之间的多模态信息融合,这可能会导致 RETFound 性能的进一步提高。
最后,一些临床相关信息,例如人口统计和视敏度(visual acuity),可能可以作为眼科研究的有效协变量,它们尚未包含在 SSL 模型中。
可以想象,通过引入更多数量的图像、探索多模式数据之间的动态交互,可以进一步增强 RETFound 在后续迭代中的表现。研究团队对于 RETFound 在未来的广泛应用持乐观态度,同时也指出,增强人与 AI 的集成对于实现医疗 AI 应用的真正落地至关重要。